Using the Mahout Naive Bayes Classifier to automatically classify Twitter messages
2013/03/13 118 Comments
 Classification algorithms can be used to automatically classify documents, images, implement spam filters and in many other domains. In this tutorial we are going to use Mahout to classify tweets using the Naive Bayes Classifier. The algorithm works by using a training set which is a set of documents already associated to a category. Using this set, the classifier determines for each word, the probability that it makes a document belong to each of the considered categories. To compute the probability that a document belongs to a category, it multiplies together the individual probability of each of its word in this category. The category with the highest probability is the one the document is most likely to belong to.
Classification algorithms can be used to automatically classify documents, images, implement spam filters and in many other domains. In this tutorial we are going to use Mahout to classify tweets using the Naive Bayes Classifier. The algorithm works by using a training set which is a set of documents already associated to a category. Using this set, the classifier determines for each word, the probability that it makes a document belong to each of the considered categories. To compute the probability that a document belongs to a category, it multiplies together the individual probability of each of its word in this category. The category with the highest probability is the one the document is most likely to belong to.
To get more details on how the Naive Bayes Classifier is implemented, you can look at the mahout wiki page.
This tutorial will give you a step-by-step description on how to create a training set, train the Naive Bayes classifier and then use it to classify new tweets.
Requirement
For this tutorial, you would need:
- jdk >= 1.6
- maven
- hadoop (preferably 1.1.1)
- mahout >= 0.7
To install hadoop and mahout, you can follow the steps described on a previous post that shows how to use the mahout recommender.
When you are done installing hadoop and mahout, make sure you set them in your PATH so you can easily call them:
export PATH=$PATH:[HADOOP_DIR]/bin:$PATH:[MAHOUT_DIR]/bin
In our tutorial, we will limit the tweets to deals by getting the tweets containing the hashtags #deal, #deals and #discount. We will classify them in the following categories:
- apparel (clothes, shoes, watches, …)
- art (Book, DVD, Music, …)
- camera
- event (travel, concert, …)
- health (beauty, spa, …)
- home (kitchen, furniture, garden, …)
- tech (computer, laptop, tablet, …)
You can get the scripts and java programs used in this tutorial from our git repository on github:
$ git clone https://github.com/fredang/mahout-naive-bayes-example.git
You can compile the java programs by typing:
$ mvn clean package assembly:single
Preparing the training set
UPDATE(2013/06/23): this section was updated to support twitter 1.1 api (1.0 was just shutdown).
As preparing the training set is very time consuming, we have provided in the source repository a training set so that you don’t need to build it. The file is data/tweets-train.tsv. If you choose to use it, you can directly jump to the next section.
To prepare a training set, we fetched the tweets with the following hashtags: #deals, #deal or #discount by using the script twitter_fetcher.py. It is using the python-tweepy 2.1 library (make sure to install the latest version as we have to use the twitter 1.1 api now). You can install it by typing:
git clone https://github.com/tweepy/tweepy.git cd tweepy sudo python setup.py install
You need to have consumer keys/secrets and access token key/secrets to use the api. If you don’t have them, simply login on the twitter website then go to: https://dev.twitter.com/apps. Then create a new application.
When you are done, you should see in the section ‘OAuth settings’, the Consumer Key and secret, and in the section ‘Your access token’, the Access Token and the Access Token secret.
Edit the file script/twitter_fetcher.py and change the following lines to use your twitter keys and secrets:
CONSUMER_KEY='REPLACE_CONSUMER_KEY' CONSUMER_SECRET='REPLACE_CONSUMER_SECRET' ACCESS_TOKEN_KEY='REPLACE_ACCESS_TOKEN_KEY' ACCESS_TOKEN_SECRET='REPLACE_ACCESS_TOKEN_SECRET'
You can now run the script:
$ python scripts/twitter_fetcher.py 5 > tweets-train.tsv
Code to fetch tweets:
import tweepy
import sys
CONSUMER_KEY='REPLACE_CONSUMER_KEY'
CONSUMER_SECRET='REPLACE_CONSUMER_SECRET'
ACCESS_TOKEN_KEY='REPLACE_ACCESS_TOKEN_KEY'
ACCESS_TOKEN_SECRET='REPLACE_ACCESS_TOKEN_SECRET'
auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET)
auth.set_access_token(ACCESS_TOKEN_KEY, ACCESS_TOKEN_SECRET)
api = tweepy.API(auth)
pageCount = 5
if len(sys.argv) >= 2:
pageCount = int(sys.argv[1])
hashtags = ['deal', 'deals', 'discount']
for tag in hashtags:
maxId = 999999999999999999999
for i in range(1, pageCount + 1):
results = api.search(q='#%s' % tag, max_id=maxId, count=100)
print len(results)
for result in results:
print result.text
maxId = min(maxId, result.id)
# only keep tweets pointing to a web page
if result.text.find("http:") != -1:
print "%s %s" % (result.id, result.text.encode('utf-8').replace('\n', ' '))
The file tweets-train.tsv contains a list of tweets in a tab separated value format. The first number is the tweet id followed by the tweet message:
308215054011194110 Limited 3-Box $20 BOGO, Supreme $9 BOGO, PTC Basketball $10 BOGO, Sterling Baseball $20 BOGO, Bowman Chrome $7 http://t.co/WMdbNFLvVZ #deals 308215054011194118 Purchase The Jeopardy! Book by Alex Trebek, Peter Barsocchini for only $4 #book #deals - http://t.co/Aw5EzlQYbs @ThriftBooksUSA 308215054011194146 #Shopping #Bargain #Deals Designer KATHY Van Zeeland Luggage & Bags @ http://t.co/GJC83p8eKh
To transform this into a training set, you can use your favorite editor and add the category of the tweet at the beginning of the line followed by a tab character:
tech 308215054011194110 Limited 3-Box $20 BOGO, Supreme $9 BOGO, PTC Basketball $10 BOGO, Sterling Baseball $20 BOGO, Bowman Chrome $7 http://t.co/WMdbNFLvVZ #deals art 308215054011194118 Purchase The Jeopardy! Book by Alex Trebek, Peter Barsocchini for only $4 #book #deals - http://t.co/Aw5EzlQYbs @ThriftBooksUSA apparel 308215054011194146 #Shopping #Bargain #Deals Designer KATHY Van Zeeland Luggage & Bags @ http://t.co/GJC83p8eKh
Make sure to use tab between the category and the tweet id and between the tweet id and the tweet message.
For the classifier to work properly, this set must have at least 50 tweets messages in each category.
Training the model with Mahout
First we need to convert the training set to the hadoop sequence file format:
$ java -cp target/twitter-naive-bayes-example-1.0-jar-with-dependencies.jar com.chimpler.example.bayes.TweetTSVToSeq data/tweets-train.tsv tweets-seq
The sequence file has as key: /[category]/ and as value: .
Code to convert tweet tsv to sequence file
public class TweetTSVToSeq {
public static void main(String args[]) throws Exception {
if (args.length != 2) {
System.err.println("Arguments: [input tsv file] [output sequence file]");
return;
}
String inputFileName = args[0];
String outputDirName = args[1];
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(configuration);
Writer writer = new SequenceFile.Writer(fs, configuration, new Path(outputDirName + "/chunk-0"),
Text.class, Text.class);
int count = 0;
BufferedReader reader = new BufferedReader(new FileReader(inputFileName));
Text key = new Text();
Text value = new Text();
while(true) {
String line = reader.readLine();
if (line == null) {
break;
}
String[] tokens = line.split("\t", 3);
if (tokens.length != 3) {
System.out.println("Skip line: " + line);
continue;
}
String category = tokens[0];
String id = tokens[1];
String message = tokens[2];
key.set("/" + category + "/" + id);
value.set(message);
writer.append(key, value);
count++;
}
writer.close();
System.out.println("Wrote " + count + " entries.");
}
}
Then we upload this file to HDFS:
$ hadoop fs -put tweets-seq tweets-seq
We can run mahout to transform the training sets into vectors using tfidf weights(term frequency x document frequency):
$ mahout seq2sparse -i tweets-seq -o tweets-vectors
It will generate the following files in HDFS in the directory tweets-vectors:
- df-count: sequence file with association word id => number of document containing this word
- dictionary.file-0: sequence file with association word => word id
- frequency.file-0: sequence file with association word id => word count
- tf-vectors: sequence file with the term frequency for each document
- tfidf-vectors: sequence file with association document id => tfidf weight for each word in the document
- tokenized-documents: sequence file with association document id => list of words
- wordcount: sequence file with association word => word count
In order to do the training and check that the classification works fine, Mahout splits the set into two sets: a training set and a testing set:
$ mahout split -i tweets-vectors/tfidf-vectors --trainingOutput train-vectors --testOutput test-vectors --randomSelectionPct 40 --overwrite --sequenceFiles -xm sequential
We use the training set to train the classifier:
$ mahout trainnb -i train-vectors -el -li labelindex -o model -ow -c
It creates the model(matrix word id x label id) and a label index(association label and label id).
To test that the classifier is working properly on the training set:
$ mahout testnb -i train-vectors -m model -l labelindex -ow -o tweets-testing -c [...] Summary ------------------------------------------------------- Correctly Classified Instances : 314 97.2136% Incorrectly Classified Instances : 9 2.7864% Total Classified Instances : 323 ======================================================= Confusion Matrix ------------------------------------------------------- a b c d e f g <--Classified as 45 0 0 0 0 0 1 | 46 a = apparel 0 35 0 0 0 0 0 | 35 b = art 0 0 34 0 0 0 0 | 34 c = camera 0 0 0 39 0 0 0 | 39 d = event 0 0 0 0 23 0 0 | 23 e = health 1 1 0 0 1 48 2 | 53 f = home 0 0 1 0 1 1 90 | 93 g = tech
And on the testing set:
$ mahout testnb -i test-vectors -m model -l labelindex -ow -o tweets-testing -c [...] Summary ------------------------------------------------------- Correctly Classified Instances : 121 78.0645% Incorrectly Classified Instances : 34 21.9355% Total Classified Instances : 155 ======================================================= Confusion Matrix ------------------------------------------------------- a b c d e f g <--Classified as 27 1 1 1 2 2 2 | 36 a = apparel 1 22 0 2 1 0 0 | 26 b = art 0 1 27 1 0 0 1 | 30 c = camera 0 1 0 23 4 0 0 | 28 d = event 0 1 0 2 9 2 0 | 14 e = health 0 1 1 1 2 13 1 | 19 f = home 0 0 2 0 0 0 0 | 2 g = tech
If the percentage of correctly classified instance is too low, you might need to improve your training set by adding more tweets or by changing your categories to not have too many similar categories or by removing categories that are used very rarely. After you are done with your changes, you would need to restart the training process.
To use the classifier to classify new documents, we would need to copy several files from HDFS:
- model (matrix word id x label id)
- labelindex (mapping between a label and its id)
- dictionary.file-0 (mapping between a word and its id)
- df-count (document frequency: number of documents each word is appearing in)
$ hadoop fs -get labelindex labelindex $ hadoop fs -get model model $ hadoop fs -get tweets-vectors/dictionary.file-0 dictionary.file-0 $ hadoop fs -getmerge tweets-vectors/df-count df-count
To get some new tweets to classify, you can run the twitter fetcher again(or use the one provided in data/tweets-to-classify-tsv):
$ python scripts/twitter_fetcher.py 1 > tweets-to-classify.tsv
Now we can run the classifier on this file:
$ java -cp target/twitter-naive-bayes-example-1.0-jar-with-dependencies.jar com.chimpler.example.bayes.Classifier model labelindex dictionary.file-0 df-count data/tweets-to-classify.tsv Number of labels: 7 Number of documents: 486 Tweet: 309836558624768000 eBay - Porter Cable 18V Ni CAD 2-Tool Combo Kit (Refurbished) $56.99 http://t.co/pCSSlSq2c1 #Deal - http://t.co/QImHB6xJ5b apparel: -252.96630831136127 art: -246.9351025603821 camera: -262.28340417385357 event: -262.5573608070056 health: -238.17884382282813 home: -253.05135616792995 tech: -232.9118 41377148 => tech Tweet: 309836557379043329 Newegg - BenQ GW2750HM 27" Widescreen LED Backlight LCD Monitor $209.99 http://t.co/6ezbjGZIta #Deal - http://t.co/QImHB6xJ5b apparel: -287.5588179141781 art: -284.27401807389435 camera: -278.4968305457808 event: -292.56786244190556 health: -292.22158238362204 home: -281.9809996515652 tech: -253.34354 804349476 => tech Tweet: 309836556355657728 J and R - Roku 3 Streaming Player 4200R $89.99 http://t.co/BAaMEmEdCm #Deal - http://t.co/QImHB6xJ5b apparel: -192.44260718853357 art: -187.6881145121525 camera: -175.8783440835461 event: -191.74948688734446 health: -190.45406023882765 home: -192.9107077937349 tech: -185.52068 485514894 => camera Tweet: 309836555248361472 eBay - Adidas Adicross 2011 Men's Spikeless Golf Shoes $42.99 http://t.co/oRt8JIQB6v #Deal - http://t.co/QImHB6xJ5b apparel: -133.86214565455646 art: -174.44106424825426 camera: -188.66719939648308 event: -188.83296276708387 health: -188.188838820323 home: -178.13519042380085 tech: -190.7717 2248114303 => apparel Tweet: 309836554187202560 Buydig - Tamron 18-270mm Di Lens for Canon + Canon 50mm F/1.8 Lens $464 http://t.co/Dqj9DdqmTf #Deal - http://t.co/QImHB6xJ5b apparel: -218.82418584296866 art: -228.25052760371423 camera: -183.46066199290763 event: -245.186963518965 health: -244.70464331200444 home: -236.16560862254997 tech: -244.4118 6823539707 => camera
Code to classify the tweets using the model and the dictionary file:
public class Classifier {
public static Map<String, Integer> readDictionnary(Configuration conf, Path dictionnaryPath) {
Map<String, Integer> dictionnary = new HashMap<String, Integer>();
for (Pair<Text, IntWritable> pair : new SequenceFileIterable<Text, IntWritable>(dictionnaryPath, true, conf)) {
dictionnary.put(pair.getFirst().toString(), pair.getSecond().get());
}
return dictionnary;
}
public static Map<Integer, Long> readDocumentFrequency(Configuration conf, Path documentFrequencyPath) {
Map<Integer, Long> documentFrequency = new HashMap<Integer, Long>();
for (Pair<IntWritable, LongWritable> pair : new SequenceFileIterable<IntWritable, LongWritable>(documentFrequencyPath, true, conf)) {
documentFrequency.put(pair.getFirst().get(), pair.getSecond().get());
}
return documentFrequency;
}
public static void main(String[] args) throws Exception {
if (args.length < 5) { System.out.println("Arguments: [model] [label index] [dictionnary] [document frequency] "); return; } String modelPath = args[0]; String labelIndexPath = args[1]; String dictionaryPath = args[2]; String documentFrequencyPath = args[3]; String tweetsPath = args[4]; Configuration configuration = new Configuration(); // model is a matrix (wordId, labelId) => probability score
NaiveBayesModel model = NaiveBayesModel.materialize(new Path(modelPath), configuration);
StandardNaiveBayesClassifier classifier = new StandardNaiveBayesClassifier(model);
// labels is a map label => classId
Map<Integer, String> labels = BayesUtils.readLabelIndex(configuration, new Path(labelIndexPath));
Map<String, Integer> dictionary = readDictionnary(configuration, new Path(dictionaryPath));
Map<Integer, Long> documentFrequency = readDocumentFrequency(configuration, new Path(documentFrequencyPath));
// analyzer used to extract word from tweet
Analyzer analyzer = new DefaultAnalyzer();
int labelCount = labels.size();
int documentCount = documentFrequency.get(-1).intValue();
System.out.println("Number of labels: " + labelCount);
System.out.println("Number of documents in training set: " + documentCount);
BufferedReader reader = new BufferedReader(new FileReader(tweetsPath));
while(true) {
String line = reader.readLine();
if (line == null) {
break;
}
String[] tokens = line.split("\t", 2);
String tweetId = tokens[0];
String tweet = tokens[1];
System.out.println("Tweet: " + tweetId + "\t" + tweet);
Multiset words = ConcurrentHashMultiset.create();
// extract words from tweet
TokenStream ts = analyzer.reusableTokenStream("text", new StringReader(tweet));
CharTermAttribute termAtt = ts.addAttribute(CharTermAttribute.class);
ts.reset();
int wordCount = 0;
while (ts.incrementToken()) {
if (termAtt.length() > 0) {
String word = ts.getAttribute(CharTermAttribute.class).toString();
Integer wordId = dictionary.get(word);
// if the word is not in the dictionary, skip it
if (wordId != null) {
words.add(word);
wordCount++;
}
}
}
// create vector wordId => weight using tfidf
Vector vector = new RandomAccessSparseVector(10000);
TFIDF tfidf = new TFIDF();
for (Multiset.Entry entry:words.entrySet()) {
String word = entry.getElement();
int count = entry.getCount();
Integer wordId = dictionary.get(word);
Long freq = documentFrequency.get(wordId);
double tfIdfValue = tfidf.calculate(count, freq.intValue(), wordCount, documentCount);
vector.setQuick(wordId, tfIdfValue);
}
// With the classifier, we get one score for each label
// The label with the highest score is the one the tweet is more likely to
// be associated to
Vector resultVector = classifier.classifyFull(vector);
double bestScore = -Double.MAX_VALUE;
int bestCategoryId = -1;
for(Element element: resultVector) {
int categoryId = element.index();
double score = element.get();
if (score > bestScore) {
bestScore = score;
bestCategoryId = categoryId;
}
System.out.print(" " + labels.get(categoryId) + ": " + score);
}
System.out.println(" => " + labels.get(bestCategoryId));
}
}
}
Most of the tweets are classified properly but some are not. For example, the tweet “J and R – Roku 3 Streaming Player 4200R $89.99” is incorrectly classified as camera. To fix that, we can add this tweet to the training set and classify it as tech. You can do the same for the other tweets which are incorrectly classified. When you are done, you can repeat the training process and check the results again.
Conclusion
In this tutorial we have seen how to build a training set, then how to use it with Mahout to train the Naive Bayes model. We showed how to test the classifier and how to improve the training set to get a better classification. Finally we use it to build an application to automatically assign a category to a tweet. In this post, we only study one Mahout classifier among many others: SGD, SVM, Neural Network, Random Forests, …. We will see in future posts how to use them.
Misc
View content of sequence files
To show the content of a file in HDFS, you can use the command
$ hadoop fs -text [FILE_NAME]
However, there might be some sequence file which are encoded using mahout classes. You can tell hadoop where to find those classes by editing the file [HADOOP_DIR]conf/hadoop-env.sh and add the following line:
export HADOOP_CLASSPATH=[MAHOUT_DIR]/mahout-math-0.7.jar:[MAHOUT_DIR]/mahout-examples-0.7-job.jar
and restart hadoop.
You can use the command mahout seqdumper:
$ mahout seqdumper -i [FILE_NAME]
View words which are the most representative of each categories
You can use the class TopCategoryWords that shows the top 10 words of each category.
public class TopCategoryWords {
public static Map<Integer, String> readInverseDictionnary(Configuration conf, Path dictionnaryPath) {
Map<Integer, String> inverseDictionnary = new HashMap<Integer, String>();
for (Pair<Text, IntWritable> pair : new SequenceFileIterable<Text, IntWritable>(dictionnaryPath, true, conf)) {
inverseDictionnary.put(pair.getSecond().get(), pair.getFirst().toString());
}
return inverseDictionnary;
}
public static Map<Integer, Long> readDocumentFrequency(Configuration conf, Path documentFrequencyPath) {
Map<Integer, Long> documentFrequency = new HashMap<Integer, Long>();
for (Pair<IntWritable, LongWritable> pair : new SequenceFileIterable<IntWritable, LongWritable>(documentFrequencyPath, true, conf)) {
documentFrequency.put(pair.getFirst().get(), pair.getSecond().get());
}
return documentFrequency;
}
public static class WordWeight implements Comparable {
private int wordId;
private double weight;
public WordWeight(int wordId, double weight) {
this.wordId = wordId;
this.weight = weight;
}
public int getWordId() {
return wordId;
}
public Double getWeight() {
return weight;
}
@Override
public int compareTo(WordWeight w) {
return -getWeight().compareTo(w.getWeight());
}
}
public static void main(String[] args) throws Exception {
if (args.length < 4) { System.out.println("Arguments: [model] [label index] [dictionnary] [document frequency]"); return; } String modelPath = args[0]; String labelIndexPath = args[1]; String dictionaryPath = args[2]; String documentFrequencyPath = args[3]; Configuration configuration = new Configuration(); // model is a matrix (wordId, labelId) => probability score
NaiveBayesModel model = NaiveBayesModel.materialize(new Path(modelPath), configuration);
StandardNaiveBayesClassifier classifier = new StandardNaiveBayesClassifier(model);
// labels is a map label => classId
Map<Integer, String> labels = BayesUtils.readLabelIndex(configuration, new Path(labelIndexPath));
Map<Integer, String> inverseDictionary = readInverseDictionnary(configuration, new Path(dictionaryPath));
Map<Integer, Long> documentFrequency = readDocumentFrequency(configuration, new Path(documentFrequencyPath));
int labelCount = labels.size();
int documentCount = documentFrequency.get(-1).intValue();
System.out.println("Number of labels: " + labelCount);
System.out.println("Number of documents in training set: " + documentCount);
for(int labelId = 0 ; labelId < model.numLabels() ; labelId++) {
SortedSet wordWeights = new TreeSet();
for(int wordId = 0 ; wordId < model.numFeatures() ; wordId++) { WordWeight w = new WordWeight(wordId, model.weight(labelId, wordId)); wordWeights.add(w); } System.out.println("Top 10 words for label " + labels.get(labelId)); int i = 0; for(WordWeight w: wordWeights) { System.out.println(" - " + inverseDictionary.get(w.getWordId()) + ": " + w.getWeight()); i++; if (i >= 10) {
break;
}
}
}
}
}
$ java -cp target/twitter-naive-bayes-example-1.0-jar-with-dependencies.jar com.chimpler.example.bayes.TopCategoryWords model labelindex dictionary.file-0 df-count
Top 10 words for label camera
– digital: 70.05728101730347
– camera: 63.875202655792236
– canon: 53.79892921447754
– mp: 49.64586567878723
– nikon: 47.830992698669434
– slr: 45.931694984436035
– sony: 44.55785942077637
– lt: 37.998433113098145
– http: 29.718397855758667
– t.co: 29.65730857849121
Top 10 words for label event
– http: 33.16791915893555
– t.co: 33.09973907470703
– deals: 26.246684789657593
– days: 25.533835887908936
– hotel: 22.658542156219482
– discount: 19.89004611968994
– amp: 19.645113945007324
– spend: 18.805208206176758
– suite: 17.21832275390625
– deal: 16.84959626197815
[…]
Running the training without splitting the data into testing and training set
You can run the training just after having executed the mahout seq2sparse command:
$ mahout trainnb -i tweets-vectors/tfidf-vectors -el -li labelindex -o model -ow -c
Using your own testing set with mahout
Previously, we showed how to generate a testing set from the training set using the mahout split command.
In this section, we are going to describe how to use our own testing set and run mahout to check the accuracy of the testing set.
We have a small testing set in data/tweets-test-set.tsv that we are transforming into a tfidf vector sequence file:
the tweet words are converted into word id using the dictionary file and are associated to their tf x idf value:
public class TweetTSVToTrainingSetSeq {
public static Map<String, Integer> readDictionnary(Configuration conf, Path dictionnaryPath) {
Map<String, Integer> dictionnary = new HashMap<String, Integer>();
for (Pair<Text, IntWritable> pair : new SequenceFileIterable<Text, IntWritable>(dictionnaryPath, true, conf)) {
dictionnary.put(pair.getFirst().toString(), pair.getSecond().get());
}
return dictionnary;
}
public static Map<Integer, Long> readDocumentFrequency(Configuration conf, Path documentFrequencyPath) {
Map<Integer, Long> documentFrequency = new HashMap<Integer, Long>();
for (Pair<IntWritable, LongWritable> pair : new SequenceFileIterable<IntWritable, LongWritable>(documentFrequencyPath, true, conf)) {
documentFrequency.put(pair.getFirst().get(), pair.getSecond().get());
}
return documentFrequency;
}
public static void main(String[] args) throws Exception {
if (args.length < 4) {
System.out.println("Arguments: [dictionnary] [document frequency] [output file]");
return;
}
String dictionaryPath = args[0];
String documentFrequencyPath = args[1];
String tweetsPath = args[2];
String outputFileName = args[3];
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(configuration);
Map<String, Integer> dictionary = readDictionnary(configuration, new Path(dictionaryPath));
Map<Integer, Long> documentFrequency = readDocumentFrequency(configuration, new Path(documentFrequencyPath));
int documentCount = documentFrequency.get(-1).intValue();
Writer writer = new SequenceFile.Writer(fs, configuration, new Path(outputFileName),
Text.class, VectorWritable.class);
Text key = new Text();
VectorWritable value = new VectorWritable();
Analyzer analyzer = new DefaultAnalyzer();
BufferedReader reader = new BufferedReader(new FileReader(tweetsPath));
while(true) {
String line = reader.readLine();
if (line == null) {
break;
}
String[] tokens = line.split("\t", 3);
String label = tokens[0];
String tweetId = tokens[1];
String tweet = tokens[2];
key.set("/" + label + "/" + tweetId);
Multiset words = ConcurrentHashMultiset.create();
// extract words from tweet
TokenStream ts = analyzer.reusableTokenStream("text", new StringReader(tweet));
CharTermAttribute termAtt = ts.addAttribute(CharTermAttribute.class);
ts.reset();
int wordCount = 0;
while (ts.incrementToken()) {
if (termAtt.length() > 0) {
String word = ts.getAttribute(CharTermAttribute.class).toString();
Integer wordId = dictionary.get(word);
// if the word is not in the dictionary, skip it
if (wordId != null) {
words.add(word);
wordCount++;
}
}
}
// create vector wordId => weight using tfidf
Vector vector = new RandomAccessSparseVector(10000);
TFIDF tfidf = new TFIDF();
for (Multiset.Entry entry:words.entrySet()) {
String word = entry.getElement();
int count = entry.getCount();
Integer wordId = dictionary.get(word);
// if the word is not in the dictionary, skip it
Long freq = documentFrequency.get(wordId);
double tfIdfValue = tfidf.calculate(count, freq.intValue(), wordCount, documentCount);
vector.setQuick(wordId, tfIdfValue);
}
value.set(vector);
writer.append(key, value);
}
writer.close();
}
}
To run the program:
$ java -cp target/twitter-naive-bayes-example-1.0-jar-with-dependencies.jar com.chimpler.example.bayes.TweetTSVToTrainingSetSeq dictionary.file-0 df-count data/tweets-test-set.tsv tweets-test-set.seq
To copy the generated seq file to hdfs:
$ hadoop fs -put tweets-test-set.seq tweets-test-set.seq
To run the mahout testnb on this sequence file:
$ mahout testnb -i tweets-test-set.seq -m model -l labelindex -ow -o tweets-test-output -c Summary ------------------------------------------------------- Correctly Classified Instances : 5 18.5185% Incorrectly Classified Instances : 22 81.4815% Total Classified Instances : 27 ======================================================= Confusion Matrix ------------------------------------------------------- a b c d e f g <--Classified as 2 1 0 1 3 0 1 | 8 a = apparel 0 0 0 2 0 0 1 | 3 b = art 0 0 0 0 1 0 0 | 1 c = camera 0 0 0 2 1 0 0 | 3 d = event 0 0 0 1 1 0 0 | 2 e = health 0 0 0 2 0 0 1 | 3 f = home 0 3 0 1 0 3 0 | 7 g = tech
Cleanup files
In case you want to rerun the classification, an easy way to delete all the files in your home in HDFS is by typing:
$ hadoop fs -rmr \*
Errors
When running the script to convert the tweet TSV message, I got the following errors:
Skip line: tech 309167277155168257 Easy web hosting. $4.95 - http://t.co/0oUGS6Oj0e - Review/Coupon- http://t.co/zdgH4kv5sv #wordpress #deal #bluehost #blue host Skip line: art 309167270989541376 Beautiful Jan Royce Conant Drawing of Jamaica - 1982 - Rare CT Artist - Animals #CPTV #EBAY #FineArt #Deals http://t.co/MUZf5aixMz
Make sure that the category and the tweet id are followed by a tab character and not spaces.
To run the classifier on the hadoop cluster, you can read the post part 2: distribute classification with hadoop.

 Frederic Dang Ngoc
Frederic Dang Ngoc @fredang
@fredang
Can you please provide the import class statements?
Hi YP,
You can get all the scripts and codes used in this post from github: https://github.com/fredang/mahout-naive-bayes-example
For the two java classes, you can get the full sourcecode with the import class statements at:
https://github.com/fredang/mahout-naive-bayes-example/blob/master/src/main/java/com/chimpler/example/bayes/TweetTSVToSeq.java
https://github.com/fredang/mahout-naive-bayes-example/blob/master/src/main/java/com/chimpler/example/bayes/Classifier.java
hi you are blog is giving nice explanation about mahout navie bayees classification implementation. to use ur java code shall i need to include any licence please suggest me.
thank u
Hi Vanitha,
Thank you. According to the Apache licence, you should keep the licence disclaimer in the header of the file.
If you use only part of the code, it’s really up to you whether or not you want to include the licence in the header.
hi
Thank you for your reply. the classifier logic which u have implemented in java. i need to write as map reduce job. how to read model and and dictonary path using map reduce job.please suggest me .
Hi Vanitha,
There are several ways to do it. For the mapper class, you can override the method setup:
public class MyMapper extends Mapper { private static StandardNaiveBayesClassifier classifier; [...] // it gets initialized when the task is initialized public void setup(Mapper.Context context) { if (classifier == null) { // we are reading the data from the model directory in hdfs // you should see this directory when typing from the command line: // hadoop fs ls model String modelPath = "model"; NaiveBayesModel model = NaiveBayesModel.materialize(new Path(modelPath), context.getConfiguration()); classifier = new StandardNaiveBayesClassifier(model); } } public void map(K key, V value, Mapper.Context context) { // you can use the classifier object here } [...] }By defining the classifier as static, we only initialize it one time for each JVM.
To make sure that a new JVM is not started for every task, you can use the option jvm reuse and set it to -1. It can be done when you setup your mapreduce jobs:
JobConf.setNumTasksToExecutePerJvm(-1);
You can read the definition file in the Reducer class and only read it once for each JVM using the same method.
Let me know if that helps.
I tried the above method of passing a variable between setup method to mapper but no luck. It is still null.
public static class MapClass
extends Mapper{
private static StandardNaiveBayesClassifier classifier;
private static Analyzer analyzer;
protected void setup(Context context) throws IOException {
NaiveBayesModel model = NaiveBayesModel.materialize(new Path(modelPath), context.getConfiguration());
StandardNaiveBayesClassifier classifier = new StandardNaiveBayesClassifier(model);
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
TokenStream ts = analyzer.tokenStream(“text”, new StringReader(tweet));
Getting error on above line. Analyzer is null
Hi YP,
The Analyzer needs to be initialized:
analyzer = new DefaultAnalyzer();
You can look at the new post:
on how to distribute the classification on the hadoop nodes.
Hi,
really helpful article! Thanky you.
I have one (maybe stupid) question:
When creating sequence file, you are using category AND the id.
Byt what if you have data only with the known category?
I mean what if you are not able to have unique key?
(eg. you have one big file containing a pair category-text per line)
Is it ok to have repeating key values or it’s manadatory to generate those unique keys in this case?
Thanks.
Hi Michael,
Yes you need a unique key for each entry.
If you have multiple entries with the same key, each of those entries will be written in the sequence file but Mahout will only consider one of them.
You can generate an id using the line number or by applying a hash function(md5 for example) on the entry content.
Let me know if that helps
Yes, that definitely helped. Thank you.
key.set(“/” + category + “/” + id);
Still looking for some more documentation as to what the key should be. Were slashes around category a personal preference? I can’t find much docs around seq2sparse, but I was looking at http://grepcode.com/file/repo1.maven.org/maven2/org.apache.mahout/mahout-examples/0.1/org/apache/mahout/classifier/bayes/WikipediaDatasetCreatorMapper.java?av=f where the key is just [country] and value the contents. Any direction to where I can find more info (even source files) would be great!
thanks
So I am still confused a bit here – is there a reason why the key has “/” (slashes). I went through whatever mahout documentation is available and could not find the semantics of what a key should look like. Furthermore, looking at the code in WikipediaDatasetMapper, it seems like its just using as key. Any direction or examples (even source files) where I could more information about the key format would be appreciated!
http://grepcode.com/file/repo1.maven.org/maven2/org.apache.mahout/mahout-examples/0.1/org/apache/mahout/classifier/bayes/WikipediaDatasetCreatorMapper.java?av=f
thanks!
Found out why – see line 119, 131
http://grepcode.com/file/repo1.maven.org/maven2/org.apache.mahout/mahout-core/0.7/org/apache/mahout/classifier/naivebayes/BayesUtils.java?av=f
@nitin, Thanks very much for you information. I also get stuck with the format of key these days.
Also thanks chimpler for nice write up.
Hi ..
Thank you for your rply. i have tried the implementation u are suggested using void setup() the main problem is while running this job has java application it is running . but while running as map reduce job it is giving org.apache.mahout.vectorizer.DefaultAnalyzer; org.apache.lucene.analysis.Analyzer classes not found error. i have added mahout jars in side hadoop cluster . please suggest me possible solution .
Hi Vanitha,
You would need to modify the HADOOP_CLASSPATH in hadoop-1.1.1/conf/hadoop-env.sh and set it to:
export HADOOP_CLASSPATH=~/mahout-distribution-0.7/mahout-core-0.7.jar:~mahout-distribution-0.7/mahout-core-0.7-job.jar:~/mahout-distribution-0.7/mahout-math-0.7.jar:~/mahout-distribution-0.7/lib/*
If you are using maven, another option is to use the plugin assembly(http://maven.apache.org/plugins/maven-assembly-plugin/) so that your jar will contains all the dependent classes (by compiling using mvn assembly:single). With this solution, you don’t need to have the mahout jars installed on all the hadoop nodes.
Let me know if it works for you
hi ..
Thank you for ur help . now its working fine for me .
hi ..
iam working on mahout navie bayes classification . algorithum is calculating probability for each catageory multiplying each word probability in that catageory . how to display each word and its probabilities from model. please give me idea how to read a model To displaying top 5 feature set for each catageory.
Hi Vanitha,
We have just implemented a class that does that.
You can look at the code at:
https://github.com/fredang/mahout-naive-bayes-example/blob/master/src/main/java/com/chimpler/example/bayes/TopCategoryWords.java
However it’s not showing the probability but the weight of the words. The weight formula (TFxIDF) is described on this page: https://cwiki.apache.org/MAHOUT/bayesian.html (looks at CBayes)
Let me know if that helps.
Hi Chimplers, this is a great tutorial (probably the best on the net so far on this subject). I went through all the steps and all worked very well. I even applied it on my own data and I got very desirable results. The only thing that didn’t work is the class that counts the TopCategory words. I get the following error:
Exception in thread “main” java.io.FileNotFoundException: File model/naiveBayesModel.bin does not exist.
at org.apache.hadoop.fs.RawLocalFileSystem.getFileStatus(RawLocalFileSystem.java:371)
at org.apache.hadoop.fs.FilterFileSystem.getFileStatus(FilterFileSystem.java:245)
at org.apache.hadoop.fs.ChecksumFileSystem$ChecksumFSInputChecker.(ChecksumFileSystem.java:125)
at org.apache.hadoop.fs.ChecksumFileSystem.open(ChecksumFileSystem.java:283)
at org.apache.hadoop.fs.FileSystem.open(FileSystem.java:400)
at org.apache.mahout.classifier.naivebayes.NaiveBayesModel.materialize(NaiveBayesModel.java:108)
at com.chimpler.example.bayes.TopCategoryWords.main(TopCategoryWords.java:92)
Apparently the model file is missing but when I check the hadoop file location with
$ hadoop fs -ls model
and I get
Found 1 items
-rw-r–r– 1 user1 supergroup 26907 2013-04-18 14:36 /user/user1/model/naiveBayesModel.bin
The file does exist. What am I doing wrong?
Thanks in advance.
I solved it. I had not copied the model file from hdfs. It works 🙂 I can now see the TopCategoryWords :)))
thank u for ur rply . it really helped me to work on probability scores. i have an issue regarding removing stop words (have did from etc ) which doesn’t contain any useful information in the traning data . iam trying using –maxDFpersent is 60 but this option is ignoring . and not disabling stopwords from feature set. please suggest me possible options. Thanks for ur help.
Hi Vanitha,
If maxDFPercent does not remove the words used in 60% of the documents:
mahout seq2sparse -i tweets-seq -o tweets-vectors –maxDFPercent 60
You can have two options:
1) You can get the list of english stopwords:
http://www.textfixer.com/resources/common-english-words.txt
String stopWordsString = "a,able,about,across,after,all,almost,also,am,among,an,and,any,are,as,at,be,because,been,but,by,can,cannot,could,dear,did,do,does,either,else,ever,every,for,from,get,got,had,has,have,he,her,hers,him,his,how,however,i,if,in,into,is,it,its,just,least,let,like,likely,may,me,might,most,must,my,neither,no,nor,not,of,off,often,on,only,or,other,our,own,rather,said,say,says,she,should,since,so,some,than,that,the,their,them,then,there,these,they,this,tis,to,too,twas,us,wants,was,we,were,what,when,where,which,while,who,whom,why,will,with,would,yet,you,your"; Set<String> stopWords = new HashSet<String>(Sets.newHashSet(stopWordsString.split(",")));2) Or get the top X words using the documentFrequency map:
public static Map<Integer, Long> getTopWords(Map<Integer, Long> documentFrequency, int topWordsCount) { List<Map.Entry<Integer, Long>> entries = new ArrayList<Map.Entry<Integer, Long>>(documentFrequency.entrySet()); Collections.sort(entries, new Comparator<Map.Entry<Integer, Long>>() { @Override public int compare(Entry<Integer, Long> e1, Entry<Integer, Long> e2) { return -e1.getValue().compareTo(e2.getValue()); } }); Map<Integer, Long> topWords = new HashMap<Integer, Long>(); int i = 0; for(Map.Entry<Integer, Long> entry: entries) { topWords.put(entry.getKey(), entry.getValue()); i++; if (i > topWordsCount) { break; } } return topWords; } [...] Map<Integer, String> inverseDictionary = readInverseDictionnary(configuration, new Path(dictionaryPath)); Map<Integer, Long> documentFrequency = readDocumentFrequency(configuration, new Path(documentFrequencyPath)); Map<Integer, Long> topWords = getTopWords(documentFrequency, 10); Set<String> stopWords = new HashSet<String>(); for(Map.Entry<Integer, Long> entry: topWords.entrySet()) { topWords.add(inverseDictionary.get(entry.getKey())); }Then you can use this stopWords set to skip those words when computing the scores:
if (topWords.contains(word)) { // skip this word continue; }Hope that it helps.
In Mahout how can we make train vectors and test vectors for Naive Bayes Classifier manually instead of use “–randomSelectionPct” option for split. According to my understanding i had built train vectors and test vectors manually as
bin/mahout seq2sparse -i TestSet0-seq -o TestSet0-vectors
bin/mahout seq2sparse -i TrainSet0-seq -o TrainSet0-vectors
/home/marvin1/hadoop-1.0.4/bin/hadoop fs -cp /user/marvin1/TestSet0-vectors/tfidf-vectors /user/marvin1/test-vectors
/home/marvin1/hadoop-1.0.4/bin/hadoop fs -cp /user/marvin1/TrainSet0-vectors/tfidf-vectors /user/marvin1/train-vectors
But by this accuracy is just 1%. Here data was 90-10 split manually. But when i had passed complete data(train+test) to mahout and used “–randomSelectionPct 10”. Then it gives accuracy around 50%.
Please let me know what i had done wrong in this.
Hi Tarun,
When you run seq2sparse, it will convert the words into word ids and put the mapping in dictionary.file-0.
When you run:
bin/mahout seq2sparse -i TestSet0-seq -o TestSet0-vectors
bin/mahout seq2sparse -i TrainSet0-seq -o TrainSet0-vectors
The mapping word=>word id will be different in the two sets.
So the same word id will map to two different words in the testing and training set.
That’s why the accuracy you get is very low.
We have just added a new section to this post “Using your own testing set with mahout” to convert the testing set in CSV into a tf-idf vectors sequence file.
The conversion uses the same mapping word id => word id that is used in the training set.
Let us know if it helps
Ok, Thanks a lot for reply. I got it. Then whats the work around to use your own testing set with mahout. You said that, there is new section started regarding this post. Can you please provide me the url for this section?
It’s at the end of the post https://chimpler.wordpress.com/2013/03/13/using-the-mahout-naive-bayes-classifier-to-automatically-classify-twitter-messages/
Look for the section ‘Using your own testing set with mahout”
Oh… i didn’t see at above…Thanks a a lot…..It solved my problem…Now getting better result.
This is a great tutorial, thanks! I’ve a query: After we create a classifier, is there any way we can make classification on the distributed file system itself, instead of copying the model files to local system, and then running the java code for it?
Thank you Shagun.
To read directly from HDFS instead of the local filesystem, you can change the configuration object to make it uses the settings defined in core-site.xml and hdfs-site.xml in the hadoop conf directory:
Configuration configuration = new Configuration();
configuration.addResource(new Path("/opt/hadoop-1.1.1/conf/core-site.xml"));
configuration.addResource(new Path("/opt/hadoop-1.1.1/conf/hdfs-site.xml"));
With this, all the objects relying on this configuration object will read from HDFS: SequenceFileIterable, NaiveBayesModel, …
In the Classifier class, if you want to read the tweets file from HDFS instead of the local filesystem, you can use the method FileSystem.open.
Instead of:
BufferedReader reader = new BufferedReader(new FileReader(tweetsPath));
do:
FileSystem fileSystem = FileSystem.get(configuration);
BufferedReader reader = new BufferedReader(new InputStreamReader(fileSystem.open(new Path(tweetsPath))));
Let us know if that helps
Thanks for the quick reply. Correct me if I’m wrong, but the code you mentioned would make the master node read files from hdfs and do the classification at the master node. Is there a way to shift the burden of this processing onto the slave nodes?
Yes you are right Shagun, with the code above the processing will be done by your local node.
To make the processing distributed on the hadoop cluster, we can implement a map reduce job.
The map function will accept as input:
key=tweet id
value=tweet message
It will run the classification on this tweet and output:
key=tweet id
value=category id
We don’t need a reduce function.
The resulting file will contain for each tweet id, the category id that the classifier found.
There might be some optimization to prevent each hadoop thread to reload the model in memory at each execution.
We will write a post on how to do this.
Has anyone done a performance bench marking on this program? I have a 2 node cluster with 6GB Ram and 4 Core. It took 14min for predicting sentiment for 10000 rows. Input file size was 20Mb.
Sorry wrong thread !!
How can I see the Actual output i.e. the attributes,text and the predicted category instead of summary at the end of the execution of that mahout command
Hi,
If you use mahout command line you cannot get that information.
You would need to use the Classifier class provided in this post to get the attributes, text and predicted category.
With “mahout testnb”:
$ mahout testnb -i train-vectors -m model -l labelindex -ow -o tweets-testing -c
By looking at the output in tweets-testing, you can only have some information on the score:
$ mahout seqdumper -i tweets-testing/part-m-00000 Key: apparel: Value: Key: apparel: Value: {0:-131.05278244010563,1:-190.28938458545053,2:-179.34751789477707,3:-174.60141541961985,4:-174.59629190657571,5:-181.1691413925544,6:-190.3951542401648} Key: apparel: Value: {0:-66.78164807930018,1:-96.3273647506556,2:-98.71864411526653,3:-91.37887040377464,4:-89.81178537003822,5:-88.19329347217497,6:-103.1540466728606} Key: apparel: Value: {0:-283.4610288938896,1:-387.7672283868884,2:-402.0972460642157,3:-403.8214845180489,4:-403.7424530656129,5:-377.1466290217178,6:-415.06647397949877} [...]If we look at the first line, it means that one document in the testing set that was classified as apparel, has the following score when using the naives bayes classifier:
-131 for category 0(apparel)
-190 for category 1(art)
-179 for category 2(camera)
-174 for category 3(event)
-174 for category 4(health)
-181 for category 5(home)
-190 for category 6(tech)
Mahout uses this to generate the confusion matrix that is displayed in the output of “mahout testnb”
Thanks for the reply,
I got the output by redirecting it to a file, now i can use the prediction
I used the following command:
mahout seqdumper -i tweets-testing/part-m-00000 > train-output.txt
In the above case i am just getting the key value pairs, what if i want the output as the twitter userid and his tweets category. I cant get this information from {key,value},
Atleast a hint in that direction would help me
Yes the file tweets-testing/part-m-00000 does not contains the tweet id, nor the tweet message.
If you want to get the twitter user id, you would need to modify the python script that fetches the tweets so that it will write a file with the association twitter id => user id
Then you would need to change the Classifier java code in this post to output for each twitter id, the user id(that you get from the association file) and the category id with the best score.
Let me know if that helps.
Hey Hi
thanks for the tutorials its just awesome.
But I had a problem while fetching the tweets from tweeter its showing following errors:
Traceback (most recent call last):
File “scripts/twitter_fetcher.py”, line 30, in
res = urllib2.urlopen(req)
File “/usr/lib/python2.7/urllib2.py”, line 126, in urlopen
return _opener.open(url, data, timeout)
File “/usr/lib/python2.7/urllib2.py”, line 406, in open
response = meth(req, response)
File “/usr/lib/python2.7/urllib2.py”, line 519, in http_response
‘http’, request, response, code, msg, hdrs)
File “/usr/lib/python2.7/urllib2.py”, line 444, in error
return self._call_chain(*args)
File “/usr/lib/python2.7/urllib2.py”, line 378, in _call_chain
result = func(*args)
File “/usr/lib/python2.7/urllib2.py”, line 527, in http_error_default
raise HTTPError(req.get_full_url(), code, msg, hdrs, fp)
urllib2.HTTPError: HTTP Error 410: Gone
Hi Puneet,
Twitter has just turned off the v1 of their REST API.
We will update the script to use the new api (v1.1) with authentication.
In the meantime, you can look at their new api at:
https://dev.twitter.com/docs
Thanks
Thanks a lot Sir…….
Waiting for for your update
Hi Puneet,
We have updated the section ‘Preparing the training set’ to describe how to use the updated script (now uses twitter 1.1 api).
Let us know if you have any questions on that.
Thanks.
Once again thanks a lot for ur support.
Mean a while I got into new problem of ckassifying the different documemts using 20 news example of mahout in eclispe there where some error after partial map and reduce phase
this error while taking output in tsv or txt file format :— I tried using other encoding but still but yes its working fine when you use on command line
‘ascii’ codec can’t encode character u’\xfc’ in position 45: ordinal not in range(128)
Has anyone done a performance bench marking on this program? I have a 2 node cluster with 6GB Ram and 4 Core. It took 14min for predicting sentiment for 10000 rows. Input file size was 20Mb.
Quick question on the use of Hadoop – for this kind of simple classification example – is it optional or is it really necessary? I am aware that some Mahout functionality only works with Hadoop but I am not sure about the classification – could this potentially work without needing Hadoop at all?
Thanks.
Eugen.
Pingback: Using the Mahout Naive Bayes Classifier to automatically classify Twitter messages (part 2: distribute classification with hadoop) | Chimpler
Pingback: Como é bom usar IA (Inteligência Artificial) | odelot stuff
Hello, can you tell me what exactly is stored in the model-File?
Am I right when I say that in the matrix with Wort ID x Label ID the probabilities are stored, for each word to belong to each label?
For Example: word=smartphone -> category: Android (prob: 0.41) Apple (prob: 0.23)
Have you any reference where this is documented?
Thanks for answering.
Hi chimpler:
thanks for the great post. I am wondering how to do the same experiment with ngram > 1. i know it’s easy to generate the vectors from training data. something like
mahout seq2sparse -i tweets-seq/ -o tweets-vectors -ng 2
but how do you encode the text in Classifier.java? I was hoping this would be straightforward to do, but it seems to me that i need to create the bigram by hand and look up the ID from the dictionary. am I on the right track? is there a simpler way to do this? In the older version of mahout API, it seems that you can just pass in ngram size.
Hi,
Great post.
I am new to mahout and got some quesitons:
why it is needed for split ? Is this for testing purpose? Since I can image it always has new data which is needed to get classified.
2nd question is regarding to the way to use my own test set. It is strange to me why mahout didn’t provide any built-in command to help user to be able to use own test set?
Somebody essentially lend a hand to make significantly posts I might
state. This is the very first time I frequented your website page and thus far?
I amazed with the analysis you made to create this particular put up amazing.
Wonderful activity!
Hi guys,
Thank you for the excellent articles, it help me a lot. But I have one doubt.
How can I increase my training set and re-classify old twitts?
Thank you.
Hi, I have tried the example and it is excellent, however I have difficulty to run the classifier at the end. It gives the following error:
Exception in thread “main” java.lang.IllegalStateException: java.io.EOFException
at org.apache.mahout.common.iterator.sequencefile.SequenceFileIterator.computeNext(SequenceFileIterator.java:104)
which is happening when the program is trying to initially read the df-count.
Strangely, if I try to run in it distributed mode, it errors with NullPointerException at the following line of the Classifier: int documentCount = documentFrequency.get(-1).intValue();, which is again related to the document count.
Obviously, something is wrong, but can not figure it out. Train and test work perfectly.
Hi Chimpler,
I am trying to run the mahout trainnb program as follows
mahout trainnb -i tweet-vectors -el -li labelindex -o model -ow -c
I get the error pasted below. However if I do hadoop fs -ls /user/hhhh/tweet-vectors/df-count, I could see the following files in the df-count folder (part-r-00000 to part-r-00009, a _SUCESS file and _logs folder)
Exception in thread “main” java.lang.IllegalStateException: hdfs://machineinfo:8020/user/hhhh/tweet-vectors/df-count
at org.apache.mahout.common.iterator.sequencefile.SequenceFileDirIterator$1.apply(SequenceFileDirIterator.java:115)
at org.apache.mahout.common.iterator.sequencefile.SequenceFileDirIterator$1.apply(SequenceFileDirIterator.java:106)
at com.google.common.collect.Iterators$8.transform(Iterators.java:860)
at com.google.common.collect.TransformedIterator.next(TransformedIterator.java:48)
at com.google.common.collect.Iterators$5.hasNext(Iterators.java:597)
at com.google.common.collect.ForwardingIterator.hasNext(ForwardingIterator.java:43)
at org.apache.mahout.classifier.naivebayes.BayesUtils.writeLabelIndex(BayesUtils.java:122)
at org.apache.mahout.classifier.naivebayes.training.TrainNaiveBayesJob.createLabelIndex(TrainNaiveBayesJob.java:180)
at org.apache.mahout.classifier.naivebayes.training.TrainNaiveBayesJob.run(TrainNaiveBayesJob.java:94)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:65)
at org.apache.mahout.classifier.naivebayes.training.TrainNaiveBayesJob.main(TrainNaiveBayesJob.java:64)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:616)
at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:68)
at org.apache.hadoop.util.ProgramDriver.driver(ProgramDriver.java:139)
at org.apache.mahout.driver.MahoutDriver.main(MahoutDriver.java:194)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:616)
at org.apache.hadoop.util.RunJar.main(RunJar.java:160)
Caused by: java.io.FileNotFoundException: File does not exist: /user/hhhh/tweet-vectors/df-count
at org.apache.hadoop.hdfs.DFSClient$DFSInputStream.fetchLocatedBlocks(DFSClient.java:2006)
at org.apache.hadoop.hdfs.DFSClient$DFSInputStream.openInfo(DFSClient.java:1975)
at org.apache.hadoop.hdfs.DFSClient$DFSInputStream.(DFSClient.java:1967)
at org.apache.hadoop.hdfs.DFSClient.open(DFSClient.java:735)
at org.apache.hadoop.hdfs.DistributedFileSystem.open(DistributedFileSystem.java:165)
at org.apache.hadoop.io.SequenceFile$Reader.openFile(SequenceFile.java:1499)
at org.apache.hadoop.io.SequenceFile$Reader.(SequenceFile.java:1486)
at org.apache.hadoop.io.SequenceFile$Reader.(SequenceFile.java:1479)
at org.apache.hadoop.io.SequenceFile$Reader.(SequenceFile.java:1474)
at org.apache.mahout.common.iterator.sequencefile.SequenceFileIterator.(SequenceFileIterator.java:63)
at org.apache.mahout.common.iterator.sequencefile.SequenceFileDirIterator$1.apply(SequenceFileDirIterator.java:110)
sice blog we got knowledge on machine learning/mahout and please continoue to update thanking u
Hi,
A great tutorial!!
Quick question: It seems the mahout split does not seem to work as map reduce job for mahout-0.7 . It just works as sequential job. If am planning to use my own testing set, then what are my options as the approach suggested by you will not run on a hadoop cluster.
Thanks,
Rohit
how to convert csv to seq file
Hi,
DO you have any idea in mahout clustering, how can we identify in document belong to which cluster. Because it returns the result on clusterdump by terms as :
:VL-0{n=2 c=[0:2.491, 000:2.642, 1:4.209, 1,765:5.290, 1.0:4.165, 1.2:1.256, 10:2.105, 1000:2.034, 10
Top Terms:
categorization => 20.145038604736328
21578 => 14.676787376403809
22173 => 13.752102851867676
tags => 12.930264472961426
categories => 12.056022644042969
sgml => 11.829574584960938
booktitle => 11.829574584960938
inproceedings => 11.222519874572754
collection => 11.18535041809082
docs => 10.580693244934082
sameline => 10.580693244934082
stories => 10.250133514404297
hayes90b => 10.006124496459961
modlewis => 9.897332191467285
documents => 9.776784896850586
reuters => 9.625079154968262
topics => 9.590224266052246
hayes89 => 9.43386459350586
lewis91d => 9.1631498336792
formatting => 9.1631498336792
Weight : [props – optional]: Point:
:VL-1{n=2 c=[amex:1.298, ase:1.869, asx:2.488, biffex:2.237, bse:2.642, cboe:1.795, cbt:1.298, cme:1.
Top Terms:
wce => 3.3353748321533203
klce => 3.3353748321533203
jse => 3.3353748321533203
klse => 3.3353748321533203
mase => 3.0476927757263184
cse => 3.0476927757263184
mnse => 3.0476927757263184
ose => 3.0476927757263184
mise => 2.8245491981506348
stse => 2.8245491981506348
ipe => 2.8245491981506348
bse => 2.6422276496887207
To those running into the EOF exception error, I’ve narrowed the problem down to the getmerge df-count file. When “hadoop fs -getmerge tweets-vectors/df-count df-count” is executed with a cluster greater than 1 node, the merge corrupts the seq file. The workaround I’ve found for now is to run “MAHOUT_LOCAL=true mahout seq2sparse -i tweets-seq -o tweets-vectors” followed by “hadoop fs -put tweets-vectors”
thank you
Pingback: 深入淺出-Mahout分類器-NaiveBayes (Part 1) | SoMeBig Analytics Lab
This is a better fix: https://github.com/mshean2011/mahout-naive-bayes-example/commit/94a766ee988f5bba43f579ca2e95e271cbe90baf
It requires the df-count path variable to point to a directory instead of a merged file
Hey Hi Sir,
I had doubt that if we are working with ngrams while creating model what changes we need make in classifer, since now we are using combination of words in the dictionary file .
Thanks & With Regards
Puneet Arora
Hi,
I’m trying to implement the tutorial but I keep having the error when running the classifier.
SLF4J: Failed to load class “org.slf4j.impl.StaticLoggerBinder”.
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
Exception in thread “main” java.lang.IllegalStateException: java.io.EOFException
I checked the SLF4J site and they suggested to add one of their jar files to the classpath, I tried but it’s not working.. any suggestions??
Thanks.
Hi all
When I try to execute mahout trainnb -i tweet-vectors -el -li labelindex -o model -ow -c command, I take below error. My hadoop version is 2.2.0. What is your ideas to solve this problem? I think problem may belongs to my hadoop version.
Error
Exception in thread “main” java.lang.IncompatibleClassChangeError: Found interface org.apache.hadoop.mapreduce.JobContext, but class was expected
at org.apache.mahout.common.HadoopUtil.getCustomJobName(HadoopUtil.java:174)
at org.apache.mahout.common.AbstractJob.prepareJob(AbstractJob.java:614)
at org.apache.mahout.classifier.naivebayes.training.TrainNaiveBayesJob.run(TrainNaiveBayesJob.java:103)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.mahout.classifier.naivebayes.training.TrainNaiveBayesJob.main(TrainNaiveBayesJob.java:64)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:72)
at org.apache.hadoop.util.ProgramDriver.run(ProgramDriver.java:144)
at org.apache.hadoop.util.ProgramDriver.driver(ProgramDriver.java:152)
at org.apache.mahout.driver.MahoutDriver.main(MahoutDriver.java:194)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.hadoop.util.RunJar.main(RunJar.java:212)
https://groups.google.com/forum/#!topic/predictionio-user/fx3xep24H0o
Yes you are right. Yout Hadoop Version is not working with mahout at the moment. see link above. I used it with hadoop 1.1.2 which is working fine.
Same here. Did you find a solution?
I have the same issue. Did you found any solution?
Pingback: IllegalArgumentException in Mahout | Technology & Programming
Hello, great tutorial. I have two questions:
1. Is there some tutorial where i can use NGrams?
2. Is there possible to use regular text files (where folder name is category and text files are separated), not just tsv?
If somebody is facing with this exception:
Exception in thread “main” java.lang.IllegalArgumentException: Label not found: heath
It says that there is a mistake in the training set.
Solution: fix the ‘tweets-train.tsv’ label which is on the end of the training set: heath – > health
Hi, very good tutorial for the starters like me.I have a question.
Do the training data need to be in such format: Class (Category), unique_id, some training text?
I cannot understand why unique_id is needed ? I want to create a simple analysis tool for negative, neutral and positive classification. Please explain me, thank you!
I am wondering , what if training data contains more than one category? How mahaout would handle it. am trying to implement tag prediction api using Mahaout, The training data has more than one target variable (comma separated tags).
very good tutorial, I could not understand NB in mahout without it.
I got a question, the scores are all negative, why is that?
Is it because I did something wrong or is it the case for mahout.
shouldn’t the scores vary between 0 and 1
That’s a good question Tuku. The reason is because the score represents the probability of the document belonging to that category.
To compute the probability of a document belonging to a category, we compute the products of the probability of each word w to belong the category C:
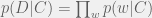
As the probability of each word to belong to the category is tiny, by doing the multiplications we are going to lose a lot of precision.
So the naive bayes implementation is using a log scale instead:

As the logarithm of a number between 0 and 1 is negative, its sum are also negative.
sir please tell about “Using the Mahout Naive Bayes Classifier to automatically classify the images”
Is this tested with mahout 0.9?
I’m running this on a single node clusted on mahout 0.9 and hadoop 1.2.1 and am getting all sorts of errors when executing
mahout seq2sparse -i tweets-seq -o tweets-vectorsHello,
I have a question about using my own testing set with mahout. How do you calculate the tfidf of the new document? I see that you get line by line the new document, you calculate the tf of words that this line has, but when you calculate the tfidf i dont understand why you use the training documents. Why you use the df and documentcount of the training documents and not the current documents?
I really appreciate any help you can provide.
Thanks a lot! 😀 Saved our asses for college project.
Hii chimpler,
i m getting this error when i try to run the command
mahout seq2sparse -i tweets-seq -o tweets-vectors
hduser@ubuntu:~$ cd /usr/local/mahout/trunk
hduser@ubuntu:/usr/local/mahout/trunk$ sudo bin/mahout seq2sparse -i tweets-seq -o tweets-vectors
[sudo] password for hduser:
Error: JAVA_HOME is not set.
I have set JAVA_HOME in .bashrc and .profile correctly
in .profile file
M2_HOME=”/usr/local/apache-maven/apache-maven-3.1.1″
M2=$M2_HOME/bin
MAVEN_OPTS=”-Xms256m -Xmx512m”
# set PATH so it includes user’s private bin if it exists
if [ -d “$M2″ ] ; then
PATH=”$M2:$PATH”
fi
export JAVA_HOME=”/usr/lib/jvm/jdk1″
PATH=”$JAVA_HOME/bin:$PATH”
in .bashrc
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
export MAHOUT_HOME=/usr/local/mahout/trunk
export PATH=$PATH:$MAHOUT_HOME/bin
export M2_HOME=/usr/local/apache-maven/apache-maven-3.1.1
export PATH=$PATH:$M2_HOME/bin
Please help me what is wrong??
Thanx!!
Hello Chimpler,
i m getting this error when i try to run the command
mahout seq2sparse -i tweets-seq -o tweets-vectors
hduser@ubuntu:~$ cd /usr/local/mahout/trunk
hduser@ubuntu:/usr/local/mahout/trunk$ sudo bin/mahout seq2sparse -i tweets-seq -o tweets-vectors
[sudo] password for hduser:
Error: JAVA_HOME is not set.
I have set JAVA_HOME in .bashrc and .profile correctly
in .profile file
M2_HOME=”/usr/local/apache-maven/apache-maven-3.1.1″
M2=$M2_HOME/bin
MAVEN_OPTS=”-Xms256m -Xmx512m”
# set PATH so it includes user’s private bin if it exists
if [ -d “$M2” ] ; then
PATH=”$M2:$PATH”
fi
export JAVA_HOME=”/usr/lib/jvm/jdk1″
PATH=”$JAVA_HOME/bin:$PATH”
in .bashrc
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
export MAHOUT_HOME=/usr/local/mahout/trunk
export PATH=$PATH:$MAHOUT_HOME/bin
export M2_HOME=/usr/local/apache-maven/apache-maven-3.1.1
export PATH=$PATH:$M2_HOME/bin
Thanx!!
Pingback: Keyword Extraction | sjsubigdata
Hey! Awesome blog. Helped a lot and got the desired results. 😀
I have a doubt though. Is the classifier model being built as a map-reduce job?
If so is it on the local node or as map-reduce jobs on a distributed cluster with slave nodes too?
Hello
In above example, documentFrequency.get(-1).intValue is giving null. Am I missing something…Please help..!!
Hi chimpler,
I am having a strange error when testing. Just to let you know I am using the local file system purely. I am not using any hdfs. The training outputs a model and now I want to test this model. I tried using a separate test set and even the training set itself but I get the following error:
java.lang.Exception: java.lang.IllegalStateException: Unable to find cached files!
at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:354) ~[hadoop-core-1.2.1.jar:na]
java.lang.IllegalStateException: Unable to find cached files!
at com.google.common.base.Preconditions.checkState(Preconditions.java:150) ~[guava-15.0.jar:na]
at org.apache.mahout.common.HadoopUtil.getCachedFiles(HadoopUtil.java:300) ~[mahout-core-0.9.jar:0.9]
at org.apache.mahout.common.HadoopUtil.getSingleCachedFile(HadoopUtil.java:281) ~[mahout-core-0.9.jar:0.9]
at org.apache.mahout.classifier.naivebayes.test.BayesTestMapper.setup(BayesTestMapper.java:50) ~[mahout-core-0.9.jar:0.9]
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:142) ~[hadoop-core-1.2.1.jar:na]
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:764) ~[hadoop-core-1.2.1.jar:na]
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:364) ~[hadoop-core-1.2.1.jar:na]
at org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable.run(LocalJobRunner.java:223) ~[hadoop-core-1.2.1.jar:na]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471) ~[na:1.7.0_55]
at java.util.concurrent.FutureTask.run(FutureTask.java:262) ~[na:1.7.0_55]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) ~[na:1.7.0_55]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) ~[na:1.7.0_55]
at java.lang.Thread.run(Thread.java:744) ~[na:1.7.0_55]
map 0% reduce 0%
So then I added the -seq argument and it prints a confusion matrix but all the values are 0 and all the percentages have a question mark on them.
Have you encountered this?