Finding association rules with Mahout Frequent Pattern Mining
2013/05/02 21 Comments
 Association Rule Learning is a method to find relations between variables in a database. For instance, using shopping receipts, we can find association between items: bread is often purchased with peanut butter or chips and beer are often bought together. In this post, we are going to use the Mahout Frequent Pattern Mining implementation to find the associations between items using a list of shopping transactions. For details on the algorithms(apriori and fpgrowth) used to find frequent patterns, you can look at “The comparative study of apriori and FP-growth algorithm” from Deepti Pawar.
Association Rule Learning is a method to find relations between variables in a database. For instance, using shopping receipts, we can find association between items: bread is often purchased with peanut butter or chips and beer are often bought together. In this post, we are going to use the Mahout Frequent Pattern Mining implementation to find the associations between items using a list of shopping transactions. For details on the algorithms(apriori and fpgrowth) used to find frequent patterns, you can look at “The comparative study of apriori and FP-growth algorithm” from Deepti Pawar.
EDIT 2014-01-08: updated link to data sample marketbasket.csv (old link was dead). Corrected lift computation. Thanks Felipe F. for pointing the error in the formula.
Requirement
For this tutorial, you would need:
- jdk >= 1.6
- maven
- hadoop (preferably 1.1.1)
- mahout >= 0.7
To install hadoop and mahout, you can follow the steps described on a previous post that shows how to use the mahout recommender.
When you are done installing hadoop and mahout, make sure you set them in your PATH so you can easily call them:
export PATH=$PATH:[HADOOP_DIR]/bin:$PATH:[MAHOUT_DIR]/bin
You can get the sourcecode used in this tutorial from the github repository:
$ git clone https://github.com/fredang/mahout-frequent-pattern-mining-example.git
To compile the project:
$ mvn clean package assembly:single
For this post, we are using a data set of transactions from a grocery store. You can download the file marketbasket.csv from Dr. Tariq Mahmood Website. The CSV contains data in the following format:
| Hair Conditioner | Lemons | Standard coffee | Frozen Chicken Wings | Beets | Fat Free Hamburger | Sugar Cookie | … |
|---|---|---|---|---|---|---|---|
| false | false | true | false | false | false | true | … |
| true | true | false | false | false | false | true | … |
| false | false | false | true | true | true | false | … |
| … | … | … | … | … | … | … | … |
Each line represents a customer basket. For instance in the first transaction, the customer bought a coffee and a sugar cookie. To use the mahout frequent pattern mining, we need to convert this data into the following format:
[item id1], [item id2], [item id3] 0, 2, 6, ... 0, 1, 6, ... 4, 5, ... ...
Code to convert the csv to dat file:
public class ConvertCsvToDat {
public static void main(String args[]) throws Exception {
if (args.length != 1) {
System.err.println("Arguments: [marketbasket.csv path]");
return;
}
String csvFilename = args[0];
BufferedReader csvReader = new BufferedReader(new FileReader(csvFilename));
// with the first line we can get the mapping id, text
String line = csvReader.readLine();
String[] tokens = line.split(",");
FileWriter mappingWriter = new FileWriter("mapping.csv");
int i = 0;
for(String token: tokens) {
mappingWriter.write(token.trim() + "," + i + "\n");
i++;
}
mappingWriter.close();
FileWriter datWriter = new FileWriter("output.dat");
int transactionCount = 0;
while(true) {
line = csvReader.readLine();
if (line == null) {
break;
}
tokens = line.split(",");
i = 0;
boolean isFirstElement = true;
for(String token: tokens) {
if (token.trim().equals("true")) {
if (isFirstElement) {
isFirstElement = false;
} else {
datWriter.append(",");
}
datWriter.append(Integer.toString(i));
}
i++;
}
datWriter.append("\n");
transactionCount++;
}
datWriter.close();
System.out.println("Wrote " + transactionCount + " transactions.");
}
}
To run the program:
$ java -cp target/mahout-frequent-pattern-mining-example-1.0-jar-with-dependencies.jar com.chimpler.example.fpm.ConvertCsvToDat [marketbasket.csv path] Wrote 1361 transactions.
This program creates two files:
- output.dat: contains the transaction data in the new format
- mapping.csv: contains the mapping between the item name and the item id
To run the Mahout frequent pattern mining, we need first to copy the file output.dat to HDFS:
$ hadoop fs -put output.dat output.dat
Now we can run mahout:
$ mahout fpg -i output.dat -o patterns -k 10 -method mapreduce -s 2
The options:
- -k 10 means that for each item i, we find the top 10 association rules: the sets of items including the item i which occurs in the biggest number of transactions.
- -s 2 means that we only consider the sets of items which appears in more than 2 transactions
It generates several files/directories in the patterns directory:
- fList: sequence file which associates to an item the number of transactions containing that word
- frequentpatterns: sequence file which contains for each item the
- fpGrowth
- parallelcounting
We can look at the raw result:
$ mahout seqdumper -i patterns/frequentpatterns/part-r-00000
13/04/30 20:51:42 INFO common.AbstractJob: Command line arguments: {--endPhase=[2147483647], --input=[patterns/frequentpatterns/part-r-00000], --startPhase=[0], --tempDir=[temp]}
Input Path: patterns/frequentpatterns/part-r-00000
Key class: class org.apache.hadoop.io.Text Value Class: class org.apache.mahout.fpm.pfpgrowth.convertors.string.TopKStringPatterns
Key: 0: Value: ([0],80), ([141, 0],42), ([132, 0],42), ([124, 0],39), ([132, 141, 0],30), ([141, 124, 0],29), ([132, 124, 0],29), ([132, 141, 124, 0],22), ([132, 141, 153, 0],20), ([132, 141, 124, 153, 0],15)
Key: 1: Value: ([1],41), ([141, 1],25), ([132, 1],25), ([16, 1],24), ([141, 16, 1],20), ([132, 141, 1],20), ([132, 16, 1],18), ([16, 175, 1],17), ([132, 141, 16, 1],16), ([132, 141, 16, 175, 1],13)
Key: 10: Value: ([10],13), ([6, 10],8), ([126, 10],7), ([124, 10],7), ([110, 10],7), ([6, 126, 10],6), ([110, 6, 10],6), ([110, 6, 126, 10],5), ([124, 126, 10],5), ([124, 110, 6, 126, 10],4)
Key: 100: Value: ([100],43), ([141, 100],28), ([132, 100],26), ([124, 100],25), ([132, 141, 100],21), ([141, 124, 100],20), ([132, 124, 100],19), ([132, 141, 124, 100],16), ([132, 141, 252, 100],15), ([132, 141, 124, 252, 100],12)
Key: 101: Value: ([101],40), ([141, 101],23), ([132, 101],23), ([124, 101],23), ([132, 141, 101],17), ([141, 124, 101],16), ([132, 124, 101],15), ([132, 141, 16, 101],13), ([132, 141, 124, 101],11), ([132, 141, 124, 16, 101],10)
Key: 102: Value: ([102],9), ([121, 102],8), ([238, 121, 102],6), ([141, 121, 102],6), ([124, 102],6), ([141, 238, 121, 102],5), ([124, 121, 102],5), ([141, 124, 238, 121, 102],4), ([124, 217, 121, 102],4), ([141, 124, 238, 217, 121, 102],3)
[...]
The first line shows the top 10 associations with the item 0. ([0],80) means that the item 0 appears in 80 transactions. ([141, 0],42) means that the pair item 141 and item 0 appears in 42 transactions and so on. The association rules can be measured using several metrics:
- support
is the proportion of transactions containing the set X:
- confidence
is the proportion of transaction containing X which also contains Y:
- lift is the ratio of the observed support to that expected if X and Y were independent:
- conviction can be interpreted as the ratio of the expected frequency that X occurs without Y:


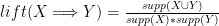
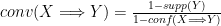
We can copy the files fList and frequentpatterns from HDFS to the local filesystem to analyze the data:
$ hadoop fs -getmerge patterns/frequentpatterns frequentpatterns.seq $ hadoop fs -get patterns/fList fList.seq
We wrote a program to read the data generated by the mahout pattern mining and show the value of the metrics for each frequent patterns.
public class ResultReader {
public static Map<Integer, Long> readFrequency(Configuration configuration, String fileName) throws Exception {
FileSystem fs = FileSystem.get(configuration);
Reader frequencyReader = new SequenceFile.Reader(fs,
new Path(fileName), configuration);
Map<Integer, Long> frequency = new HashMap<Integer, Long>();
Text key = new Text();
LongWritable value = new LongWritable();
while(frequencyReader.next(key, value)) {
frequency.put(Integer.parseInt(key.toString()), value.get());
}
return frequency;
}
public static Map<Integer, String> readMapping(String fileName) throws Exception {
Map<Integer, String> itemById = new HashMap<Integer, String>();
BufferedReader csvReader = new BufferedReader(new FileReader(fileName));
while(true) {
String line = csvReader.readLine();
if (line == null) {
break;
}
String[] tokens = line.split(",", 2);
itemById.put(Integer.parseInt(tokens[1]), tokens[0]);
}
return itemById;
}
public static void readFrequentPatterns(
Configuration configuration,
String fileName,
int transactionCount,
Map<Integer, Long> frequency,
Map<Integer, String> itemById,
double minSupport, double minConfidence) throws Exception {
FileSystem fs = FileSystem.get(configuration);
Reader frequentPatternsReader = new SequenceFile.Reader(fs,
new Path(fileName), configuration);
Text key = new Text();
TopKStringPatterns value = new TopKStringPatterns();
while(frequentPatternsReader.next(key, value)) {
long firstFrequencyItem = -1;
String firstItemId = null;
List<Pair<List, Long>> patterns = value.getPatterns();
int i = 0;
for(Pair<List, Long> pair: patterns) {
List itemList = pair.getFirst();
Long occurrence = pair.getSecond();
if (i == 0) {
firstFrequencyItem = occurrence;
firstItemId = itemList.get(0);
} else {
double support = (double)occurrence / transactionCount;
double confidence = (double)occurrence / firstFrequencyItem;
if (support > minSupport
&& confidence > minConfidence) {
List listWithoutFirstItem = new ArrayList();
for(String itemId: itemList) {
if (!itemId.equals(firstItemId)) {
listWithoutFirstItem.add(itemById.get(Integer.parseInt(itemId)));
}
}
String firstItem = itemById.get(Integer.parseInt(firstItemId));
listWithoutFirstItem.remove(firstItemId);
System.out.printf(
"%s => %s: supp=%.3f, conf=%.3f",
listWithoutFirstItem,
firstItem,
support,
confidence);
if (itemList.size() == 2) {
// we can easily compute the lift and the conviction for set of
// size 2, so do it
int otherItemId = -1;
for(String itemId: itemList) {
if (!itemId.equals(firstItemId)) {
otherItemId = Integer.parseInt(itemId);
break;
}
}
long otherItemOccurrence = frequency.get(otherItemId);
double lift = ((double)occurrence * transactionCount) / (firstFrequencyItem * otherItemOccurrence);
double conviction = (1.0 - (double)otherItemOccurrence / transactionCount) / (1.0 - confidence);
System.out.printf(
", lift=%.3f, conviction=%.3f",
lift, conviction);
}
System.out.printf("\n");
}
}
i++;
}
}
frequentPatternsReader.close();
}
public static void main(String args[]) throws Exception {
if (args.length != 6) {
System.err.println("Arguments: [transaction count] [mapping.csv path] [fList path] "
+ "[frequentPatterns path] [minSupport] [minConfidence]");
return;
}
int transactionCount = Integer.parseInt(args[0]);
String mappingCsvFilename = args[1];
String frequencyFilename = args[2];
String frequentPatternsFilename = args[3];
double minSupport = Double.parseDouble(args[4]);
double minConfidence = Double.parseDouble(args[5]);
Map<Integer, String> itemById = readMapping(mappingCsvFilename);
Configuration configuration = new Configuration();
Map<Integer, Long> frequency = readFrequency(configuration, frequencyFilename);
readFrequentPatterns(configuration, frequentPatternsFilename,
transactionCount, frequency, itemById, minSupport, minConfidence);
}
}
To run the program:
$ java -cp target/mahout-frequent-pattern-mining-example-1.0-jar-with-dependencies.jar com.chimpler.example.fpm.ResultReader 1361 mapping.csv fList.seq frequentpatterns.seq 0.04 0.4
The arguments of this program are:
- transaction count
- the file containing the mapping item => item id
- fList.seq a sequence file containing for each item id, the number of transactions containing that word
- frequentpatterns.seq the frequent patterns sequence file computed by mahout
- mininum support
- minimum confidence
To find the minimum support and minimum confidence to use, try using different values until you get relevant results. The program shows the following associations:
[Sweet Relish] => Hot Dogs: supp=0.047, conf=0.508, lift=5.959, conviction=1.859 [Eggs] => Hot Dogs: supp=0.043, conf=0.460, lift=3.751, conviction=1.626 [Hot Dog Buns] => Hot Dogs: supp=0.042, conf=0.452, lift=7.696, conviction=1.719 [White Bread] => Hot Dogs: supp=0.040, conf=0.437, lift=3.667, conviction=1.563 [Eggs] => 2pct. Milk: supp=0.052, conf=0.477, lift=3.883, conviction=1.676 [White Bread] => 2pct. Milk: supp=0.051, conf=0.470, lift=3.947, conviction=1.662 [Potato Chips] => 2pct. Milk: supp=0.045, conf=0.409, lift=4.189, conviction=1.528 [White Bread] => Tomatoes: supp=0.040, conf=0.611, lift=5.134, conviction=2.265 [White Bread] => Eggs: supp=0.055, conf=0.449, lift=3.773, conviction=1.599 [2pct. Milk] => Eggs: supp=0.052, conf=0.425, lift=3.883, conviction=1.549 [...]
The association rules are making sense: clients buying “Sweet Relish”, “Eggs”, “Hot Dog Buns” or “White Bread” are also buying “Hot Dogs”.
In this tutorial we showed how to use the mahout pattern frequent mining implementation on a grocery store transactions to find items that are often purchased together. This algorithm can be used in various other domains, for instance to find association rules in gene expressions or in population census, …

 Frederic Dang Ngoc
Frederic Dang Ngoc @fredang
@fredang
Looks great, thanks. There’s no pom file in the git repository though, so the maven build doesn’t work as is.
We have just committed the pom files to the git repository.
Thank you Eddie for pointing this out.
Great tutorial, as usual. It worked perfectly for me.
Works fine. Thanks.
Works fine, thanks,
You only calculate the lift for the 2 items rules, why didnt you calculate for the rest and how can it be done?
Thanks
Hello,
I got a problem in one command and because I am a begginner in Mahout I couldn’t solve it.
This is the command $ mahout seqdumper -i patterns/frequentpatterns/part-r-00000
and what I got from using this is
MAHOUT_LOCAL is not set; adding HADOOP_CONF_DIR to classpath.
Running on hadoop, using HADOOP_HOME=/opt/hadoop
No HADOOP_CONF_DIR set, using /opt/hadoop/conf
MAHOUT-JOB: /opt/mahout-distribution-0.6/mahout-examples-0.6-job.jar
13/12/02 11:50:34 ERROR common.AbstractJob: Unexpected -i while processing Job-Specific Options:
usage: [Generic Options] [Job-Specific Options]
Generic Options:
-archives comma separated archives to be unarchived
on the compute machines.
-conf specify an application configuration file
-D use value for given property
-files comma separated files to be copied to the
map reduce cluster
-fs specify a namenode
-jt specify a job tracker
-libjars comma separated jar files to include in the
classpath.
Unexpected -i while processing Job-Specific Options:
Usage:
[–seqFile –output –substring –count
–numItems –facets –help –tempDir –startPhase
–endPhase ]
Job-Specific Options:
–seqFile (-s) seqFile The Sequence File to read in
–output (-o) output The directory pathname for output.
–substring (-b) substring The number of chars to print out per value
–count (-c) Report the count only
–numItems (-n) numItems Output at most key value pairs
–facets (-fa) Output the counts per key. Note, if there are
a lot of unique keys, this can take up a fair
amount of memory
–help (-h) Print out help
–tempDir tempDir Intermediate output directory
–startPhase startPhase First phase to run
–endPhase endPhase Last phase to run
13/12/02 11:50:34 INFO driver.MahoutDriver: Program took 176 ms (Minutes: 0.00293)
Please I need help in this.
hi, I’am having the same problem trying to run FPG on mahout 0.8 and I can’t find the way to set the generic options for the command,
If you solved the problem can you please mention it
Regards
Hi…I have a couple of questions on the association rule program that’s present at the end . can you please help me understand..
1) looks like the association rule does not match the corresponding confidence score that you’ve calculated.
For the rule: [Sweet Relish] => Hot Dogs, I would expect the underlying confidence score formula to be P ( Hot Dogs | Sweet Relish ), but your program calculates P ( Sweet Relish | Hot Dogs ). which may not be right? should’nt this be inline to the rule X –> Y, and its confidence score P (Y | X). If thats the case, the count of Sweet Relish will not be available in the key pattern that’s operated in the loop.
2) Taking the first item from the first pattern (i.e firstItemId = itemList.get(0); ) would not always work, because key and the first item need not be same always,
Thanks
I saw that too. This program give error result
Chimpler, I was following your tutorial and it’s great, but I think your Lift is miscalculated.
(line 86) double lift = (double)occurrence / (firstFrequencyItem * otherItemOccurrence);
should be
double lift = (double) transactionCount * occurrence / (firstFrequencyItem * otherItemOccurrence);
Because Lift is a proportion between frequencies, and you doing a proportion between counts, so, in my math, you have to multiply for transactionCount to have the right values. In your output, lift is about 0.003, 0.004, meaning it’s LESS likely to purchase the product than a regular person.
Thanks for the tutorial again !
How can this be done when the rule has more than 2 items?
Well, the issue to calculate Lift is you need the know the support for all combinations. Since LIFT is defined as LIFT(A=>X) = supp( a U X ) / ( supp (a) * supp(x) ), for 2 items A and B you need to supp(ab) and supp (ab U X), and, as far as I know, mahout doesn’t calculate all composite supports… I will be studying to find a solution if I have time, but so far in my case I’m planing to use mahout’s recommendation system instead of fpGrowth. Good luck !
According to the lift formula,
lift(X -> Y) = supp(X U Y) / (supp(X) * supp(Y))
If I use the confidence formula (conf (X -> Y) = supp(X U Y) / (supp(X)), then I can replace it,
lift(X -> Y) = conf ( X -> Y) / supp(Y)
How do you calculate the supp(Y) in your code?
The formula that i suggest wil be this one.
double lift = (double)confidence / ((double)((double)firstFrequencyItem / (double)transactionCount));
I have a question. In this example specifically, what are the the minimum support and confidence specified? cause I cant see these values in the code provided. Can you help please
Pingback: Discovering frequent patterns using mahout command line | Linux Uncle
Hi.I have a problem over here.When i was trying to compile the “convertcsvtodat” file using the command ” java -cp target/mahout-frequent-pattern-mining-example-1.0-jar-with-dependencies.jar /home/yoge/Downloads/ConvertCsvToDat.java /home/yoge/Downloads/marketbasket.csv ” , Iam getting the error stating that ” Error: Could not find or load main class .home.yoge.Downloads.ConvertCsvToDat.java ” .
Kindly notify me the mistake and let me know the correct procedure.Thank you
Hi.I have a problem while i tried to run the program of ConvertCsvToDat file using
” java -cp target/mahout-frequent-pattern-mining-example-1.0-jar-with-dependencies.jar com.chimpler.example.fpm.ConvertCsvToDat [marketbasket.csv path] ” and
Iam getting the error stating that ” Error: Could not find or load main class .home.yoge.Downloads.ConvertCsvToDat.java ” .Kindly help me here.
Thank you for tutorial!
But it seems to me that your confidence implementation is not corrrect still.
In yours code:
double confidence = (double)occurrence / firstFrequencyItem;
Let’s look at formula: conf(X => Y)=support(X&Y)/support(X).
In code, occurence is value that’s coresponds to X&Y set, but firstFrequencyItem is value that corresponds to Y. So you calculate support(X&Y)/support(Y). As you can see it’s not a confidence for rule X=>Y.
Implementation should look like
double confidence = (double)occurrence / otherItemsFrequency;
But how this otherItemsFrequency can be found in mahout output files?
My prectice shows that such frequencies can be found in frequentpatterns output but not for all rules.
Hey chimpler: Nice tutorial.
One tiny problem though. The new version of mahout doesn’t have fpg included. Found out the hard way. Running it throws up ClassNotFoundException
Hi Chimpler,
I have followed the tutorial and completed the task till the output.dat file creation and mapping.csv file creation using eclipse.
After that I could not able to execute the below line
mahout fpg -i output.dat -o patterns -k 10 -method mapreduce -s 2
and its throwing the below errorRunning on hadoop, using /cygdrive/f/Hadoop/hadoop-2.5.0/bin/hadoop and HADOOP_CONF_DIR=
ERROR: Could not find mahout-examples-*.job in /cygdrive/f/Hadoop/mahout-distribution-0.9 or /cygdrive/f/Hadoop/mahout-distribution-0.9/examples/target, please run ‘mvn install’ to create the .job file
Is there any commands available for executing the below line using java code in eclipse?
mahout fpg -i output.dat -o patterns -k 10 -method mapreduce -s 2
Thanks,
Nagaraju